Header image is Birdseye Photography of City Buildings Near Trees and Mountains by Felix Mittermeier used under license CC0
People who know me know that I love movies. I always have. Whether as a child in the downstairs living room, or in a packed theatre with friends, or at drive-ins in the back of a pick-up truck, or entirely relaxed on my own. I can watch them in all kinds of places with all kinds of crowds. There’s something for every mood.
The Beauty of Film
And the types of movies! Over the years I’ve had to branch further out, and I’m so glad for that. Stylized heist films, love served with loss, the wonder that is Denmark, dramas with personality, creepy and darkly funny fantasies…I’m down for anything original with story, pace, and attitude. Not to forget, there’s a special place in my heart for the cops and bad guys, war heroes, and macho westerns on which I was raised.
Why do we like movies? There’s a social aspect, yet many of us will gladly watch them on our own. It’s because we love a good story. Those of us who appreciate film the most see it as an art form with incredible complexity and beauty. The best films have been cherished and nurtured by their creators, with a passion put into their stories, depth and purpose imbued in their characters and represented skillfully by their actors, and specifically chosen positioning and lighting by the cinematographers that makes every frame a painting. When it works, a great film is a piece of art composed by hundreds of creative and talented participants, who have collectively created something of great beauty and complexity.
 Great stories are where we find great heroes
Great stories are where we find great heroes
So why film lists? I’m talking about things such as the IMDB Top 250 and Roger Ebert’s Great Movies. A list of films is just a grouping, which might have a ranking but often does not. For many like myself, they’re a way of figuring out what to watch, through association with other films. It’s possible this incarnation becomes obsolete, as personalized recommendation engines fulfill this purpose better and better. However that wasn’t the case in the mid-2000s, when I first became interested in these lists.
Lists are a good thing for people who are a bit obsessive. When I first made a serious hobby out of movies and found the IMDB Top 250, it felt like there was so much out there that I had missed out on. At some point I wrote a little program, imdb.pl, to help me track it as I made progress (for the curious, I’ve been around 190 for a long time now). Some time later the website icheckmovies.com, or ICM, emerged, doing it so much more thoroughly and better, and imdb.pl was history. That’s an example of creative destruction in action.
Getting back into the list game
Following up on some curiosities, I decided to get my hands on data again. The existence of iCheckMovies, which killed imdb.pl, is now the very thing that enabled me to do it again, but better. I scraped all of the lists on ICM and put those into a local database. This time I’m sharing my entire code on github, so readers can follow along easily.
Here are the pieces:
- db_wrapper.py and db_wrapper_table.py A simple SQLite wrapper to keep some of the SQL line noise out of my main programs. There are better abstractions out there, but I haven’t settled on one I like, and this is lightweight
- initialize_db.py: Use db_wrapper to set up my database
- fetch_list_overview.py: Get the list of lists
- fetch_lists.py: For each list found, fetch the items on it
- analysis_queries.sql: A series of SQL queries I used for analysis
- Films.ipynb: An iPython notebook for analysis above and beyond what could be done with simple SQL
Let’s talk briefly about how some of it works, since this is a pretty common and powerful analysis paradigm. First I plan out how I want to store my data (the DB schema). Planning out my data requires clarity of thought about what questions I want to answer, what data I need to answer them, and the strongest way to represent the data to enable that. I chose SQLite for this because this is a single user application with minimal data requirements and no real-time needs, so storing the database as a file is appropriate. Then I gather it through what I call scrape-and-store, but which more generically may be described as an ETL framework. I use Beautiful Soup to parse out the data, since it can use CSS selectors to isolate information, and iterate through items programmatically.
After acquiring the data, I switched gears (and tools) to analyze it. I used a simple SQL client to perform some basic analysis and start to explore more complicated ideas. Then I used Jupyter/IPython. Switching from writing Python programs to writing Python snippets comes naturally here. The programs had defined purposes: specific outputs that they were intended to create. But analysis is open-ended, so we needs tools that let us evaluate hypotheses quickly and store the results. Jupyter let’s us interlace code and output, such that we can tell a story of what we learned and how we progressed through the analysis.
Some things I learned
Want to see an ugly error message? Try putting an extra slash in any iCheckMovies URL.
Usually when something makes you think your code has a bug, you’re right. But it’s nice to be surprised! There’s a movie that ICM thinks is named <—> (Yes, like that, with the HTTP ampersand character codes). The link doesn’t work for it, so all I know is the two lists it is on and that it was released in 1969.
 1969, known for the Apollo 11 moon landing, and the film <–>
1969, known for the Apollo 11 moon landing, and the film <–>
Image from NASA
{kind=link}
Most common tags for lists:
| Tag | # |
|---|---|
| country | 41 |
| imdb | 38 |
| website | 34 |
| award | 21 |
| institute | 17 |
| critics | 14 |
| misc | 5 |
| director | 4 |
Top 10 most common tags for films:
| Tag | # |
|---|---|
| drama | 7693 |
| comedy | 3040 |
| crime | 1780 |
| romance | 1751 |
| short | 1593 |
| action | 1337 |
| documentary | 1192 |
| horror | 1120 |
| thriller | 1118 |
| adventure | 1059 |
Films in the most lists. It sure seems like it takes a while to get on a lot of lists:
| Film | Year | # |
|---|---|---|
| 2001: A Space Odyssey | 1968 | 40 |
| Lawrence of Arabia | 1962 | 39 |
| Vertigo | 1958 | 38 |
| The Godfather | 1972 | 36 |
| Citizen Kane | 1941 | 35 |
| Ladri di biciclette | 1948 | 35 |
| Psycho | 1960 | 35 |
| Star Wars | 1977 | 35 |
| 8½ | 1963 | 34 |
| M | 1931 | 34 |
| Sunrise: A Song of Two Humans | 1927 | 34 |
| A Clockwork Orange | 1971 | 33 |
| Casablanca | 1942 | 33 |
| Apocalypse Now | 1979 | 32 |
| On the Waterfront | 1954 | 32 |
| One Flew Over the Cuckoo’s Nest | 1975 | 32 |
| Pulp Fiction | 1994 | 32 |
| Sen to Chihiro no kamikakushi | 2001 | 32 |
| Singin’ in the Rain | 1952 | 32 |
| Sunset Blvd. | 1950 | 32 |
We can check if that conclusion is true. Here are years with the most films listed. It seems like the early 70’s and the 2000’s produced a lot of listable films:
| Year | # |
|---|---|
| 1972 | 226 |
| 1969 | 224 |
| 2004 | 223 |
| 1968 | 222 |
| 1971 | 222 |
| 2002 | 222 |
| 2000 | 211 |
| 2001 | 210 |
| 1970 | 209 |
| 2003 | 208 |
| 2006 | 206 |
| 2007 | 201 |
| 1967 | 199 |
| 1986 | 199 |
| 1965 | 196 |
| 1989 | 196 |
| 1990 | 196 |
| 2005 | 196 |
| 1988 | 194 |
| 2008 | 192 |
Here’s a chart of progression by year. You can see that the last few years have some drop off, so we can expect their list progression to increase over time. The late 60’s were peak list popularity.
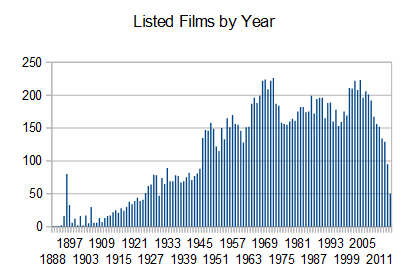
What happens if we weight the years by how many lists each film is in? The 60’s are looking even more popular.
| Year | # |
|---|---|
| 1971 | 594 |
| 2000 | 592 |
| 1968 | 579 |
| 2001 | 579 |
| 1972 | 573 |
| 2002 | 566 |
| 1967 | 561 |
| 1964 | 560 |
| 1973 | 535 |
| 1966 | 527 |
| 1969 | 526 |
| 1960 | 525 |
| 1962 | 525 |
| 2004 | 522 |
| 1988 | 521 |
| 1955 | 511 |
| 1959 | 511 |
| 1982 | 508 |
| 2003 | 508 |
| 1957 | 506 |
You know what they say, the first list is the hardest.
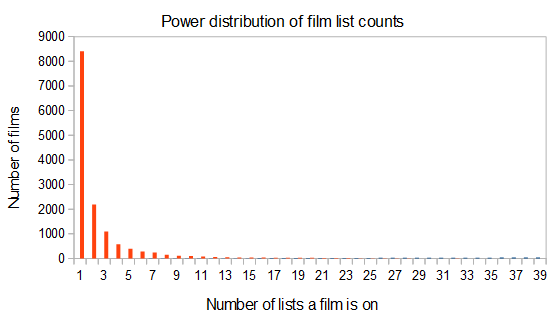
Pairwise evaluation of films
Ranking the popularity of films and years is both fun and easy, but we can reach more powerful insights through analyzing the connections more deeply. Every time two films are on the same list, that creates a connection between those two films, bound together by a classification or a critic’s seal of approval.
Evaluating these pairwise calculations is harder, because it involves calculating across every pair across each film or list, so it does not scale nicely with size. In this case, with 14,159 films, there are 100,231,561 such pairs to make.
 It took me a while to count that high
It took me a while to count that high
Image from Nate Steiner used under the public domain
That works because evaluating N films gives us (N*N - N)/2 comparisons. N*N is the matrix size. Divided by two because order doesn’t matter in a pair and we don’t want to double count the pairs, and subtract N because we don’t include the diagonal vector of the film in a pair with itself.
One way to evaluate this is with cluster analysis. Treat each list or each film as an observation, and then have the films on the list, or the lists that the film is on, as the attributes. In this case, given the amount of single-list films, this is a fairly sparse matrix. Because of the sparsity, I chose to look at a subset of films, selecting those that are represented on at least 10 lists. This is just 586 of the 14,159 total films, yet those 586 films have representation on 157 of the 174 lists. This drastically reduces the dimensionality of our data, without much reducing the connections that we want to evaluate.
If we perform some simple k-means clustering on the films, we can get some interesting clusters. I did it with 10 clusters (cluster count is a parameter into k-means). We can do a lot more nuanced cluster analysis, but I felt I wouldn’t go into too much detail unless I wanted to gather more information about the films.
| Cluster | Size | Arbitrary Description |
|---|---|---|
| 1 | 25 | I’m not sure! |
| 2 | 50 | Science fiction and fantasy |
| 3 | 146 | Classics |
| 4 | 155 | Foreign |
| 5 | 26 | Classics |
| 6 | 95 | 90’s-now and highest rated |
| 7 | 17 | Italian |
| 8 | 24 | Animated |
| 9 | 8 | Documentary |
| 10 | 40 | Very old |
Some of those are surprisingly clean cut, while on the other hand clusters 3 and 5 seem closer together to me. However, my running hypothesis is that cluster 3 is predominantly 30’s and 40’s, while cluster 5 is heavy on 50’s and 60’s movies. This would fit my impression (although validating your biases is a dangerous thing to do…) that many of these lists are grouped more on time period than anything else.
We can also perform a similar analysis across lists, rather than films. Here I use the correlation coefficient (for these binary variables this is the Phi coefficient) to evaluate similarity across all lists. I’m not surprised that They Shoot Zombies, Don’t They? and Top 500 Horror Movies have a coefficient of 0.63, Animation and Family have a 0.58, and 100 Korean Films and 100 Korean Masterpieces have 0.56. But I am surprised at the one pairing that’s much higher on the list than all of those. Sight and Sound 2012 Combined List might as well just take They Shoot Pictures, Don’t They? since they have a ridiculous correlation of 0.79.
It seems the IMDB Top 250 is something to imitate, since the Reddit Top 250, Fok! Top 250, and FilmTotal Top 250 have correlations of 0.61, 0.6, and 0.54, respectively, with it.
| List 1 | List 2 | phi | abs_phi |
|---|---|---|---|
| /lists/sight+and+sound+2012+-+combined+list/ | /lists/they+shoot+pictures+dont+they/ | 0.78909 | 0.78909 |
| /lists/they+shoot+zombies+dont+theyquestion/ | /lists/top+500+horror+movies/ | 0.631314 | 0.631314 |
| /lists/filmtotaal+top+250/ | /lists/fokexclamation+top+250/ | 0.625386 | 0.625386 |
| /lists/reddit+top+250/ | /lists/top+250/ | 0.61445 | 0.61445 |
| /lists/silent+but+not+forgotten+the+best+silen… | /lists/the+top+300+silent+era+films/ | 0.605662 | 0.605662 |
| /lists/fokexclamation+top+250/ | /lists/top+250/ | 0.600954 | 0.600954 |
| /lists/fokexclamation+top+250/ | /lists/reddit+top+250/ | 0.59405 | 0.59405 |
| /lists/1001+movies+you+must+see+before+you+die/ | /lists/they+shoot+pictures+dont+they/ | 0.58028 | 0.58028 |
| /lists/animation/ | /lists/family/ | 0.578512 | 0.578512 |
| /lists/filmtotaal+top+250/ | /lists/reddit+top+250/ | 0.573651 | 0.573651 |
It’s perhaps worth noting that very few lists actually have a negative correlation with each other. For this reason, Doubling the Canon is either a good list to use or a good list to avoid. It’ll get you films that aren’t as common on other lists, for better or worse.
The next thing I looked at was more direct pairwise comparison of films. This is probably more useful, since finding lists is not a likely end goal for many people, but finding films is a common task.
I go about doing this by computing the Chi-square kernel using scikit-learn. This will give us a number between 0 and 1 for every pairwise comparison, with a 1 indicating a perfect match. For my features I’m using which lists a film is on - I’m not even bothering including the film tags, list tags, or year.
For the second time today, I’ve been given the small blessing of thinking my code had a bug when it (surprisingly) did not. There were two films with the exact same 11 lists! Those are The Olympiad and, surprise surprise, The Olympiad Part 2. I haven’t seen either, but I have a feeling that if I watch the first I’ll be compelled to watch the second.
Conclusions
And this, finally, brings us to our title question. How is The Green Mile like American History X? If you evaluate by lists, they’re both each other’s most similar film. The Green Mile is on 13 lists, and American History X is on 11 lists, with 9 lists of overlap! They might not seem that connected stylistically or share the same themes, but they have been strongly grouped together.
I’ve covered a lot in this piece, from my love of movies to how to do pairwise correlations using film list data. We can get meaningful insight out of basic analysis with SQL, and more if we venture into more powerful tools. We have to be flexible, and adjust our techniques to the type of data we have available.
Even without gathering any real data about the films themselves, and not even using the genre or years, we can connect them based on how others have made groupings. What I’ve shown here is the basis of a very simple recommendation engine. This is a powerful purpose, and one used to great effect by organizations like Netflix and Amazon. Instead of using a finite set of published lists, we could choose to treat each user’s preferences as a list on its own, and then have a dynamic recommendation engine that changes with the audience. It could be then personalized to each user by weighting the other users according to their similarity with the user in question. With immense data, the tools to analyze it, and time, we can create great work.